
About Me
I am a Master student at Peking University, advised by Professor Bin Cui and Assistant Professor Wentao Zhang. My research interests include large language models, AI agents, and data scaling.
Before this, I obtained my bachelor’s degree in Computer Science from Renmin University of China. Previously, I conducted my internship at Tencent AI Lab and Meituan LongCat. I am currently a research intern at Alibaba Qwen.
Please feel free to reach out if you are interested in collaboration.
Educations
- Peking University (2024 - Present), Master Student in Computer Science
- Renmin University of China (2020 - 2024), B.Sc. in Computer Science
Selected Projects
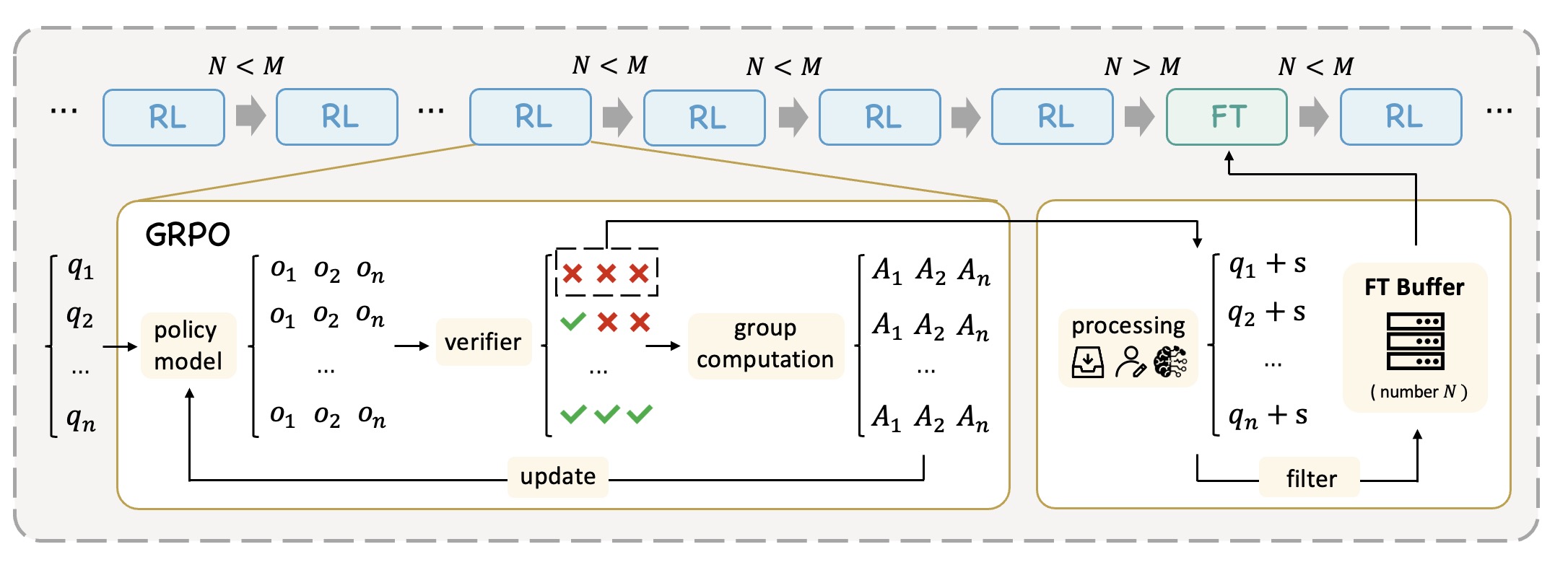
Learning What Reinforcement Learning Can’t: Interleaved Online Fine-Tuning for Hardest Questions
- Lu Ma, Hao Liang, Meiyi Qiang, Lexiang Tang, Xiaochen Ma, Zhen Hao Wong, Junbo Niu, Chengyu Shen, Runming He, Yanhao Li, Bin Cui, Wentao Zhang
- ICLR 2026.
- ReLIFT combines reinforcement learning and supervised fine-tuning in an interleaved training framework that expands LLM reasoning capabilities beyond the limits of RL alone.
- [Paper] [Code]
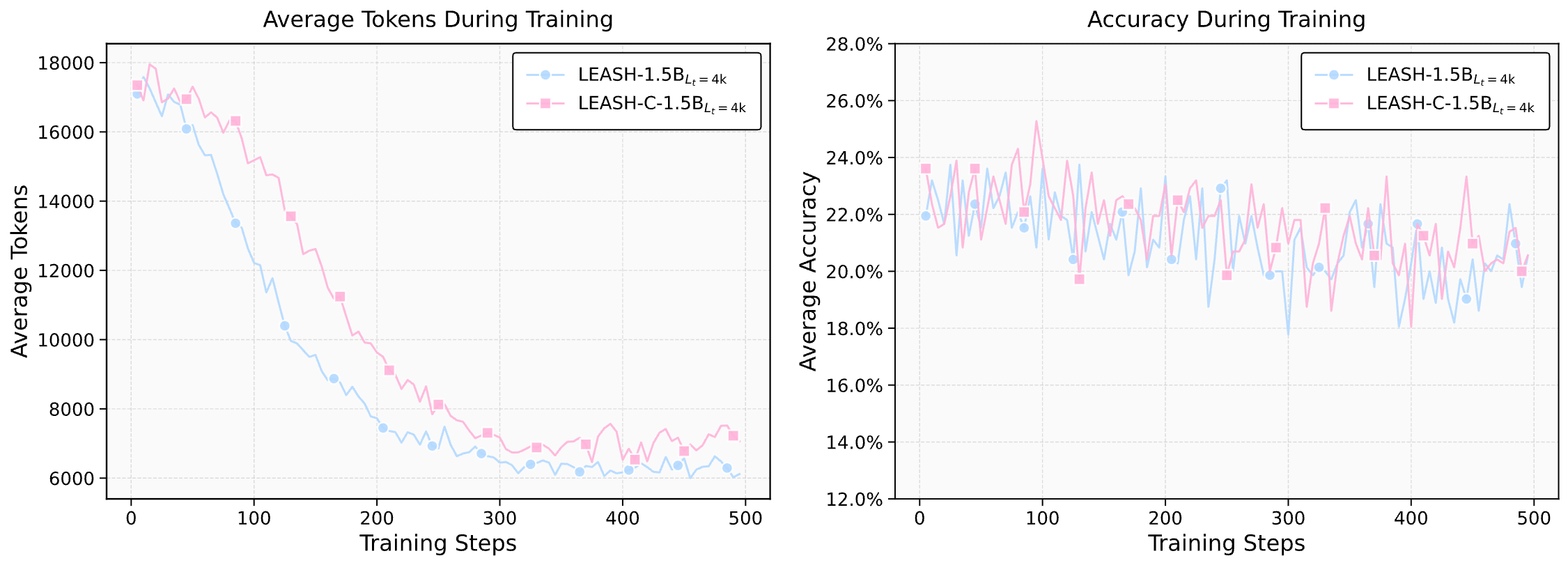
Leash: Adaptive Length Penalty and Reward Shaping for Efficient Large Reasoning Model
- Yanhao Li*, Lu Ma*, Jiaran Zhang, Lexiang Tang, Wentao Zhang, Guibo Luo
- ACL 2026.
- LEASH introduces an adaptive length-penalty mechanism for LLM reasoning using a Lagrangian primal-dual optimization framework.
- [Paper]
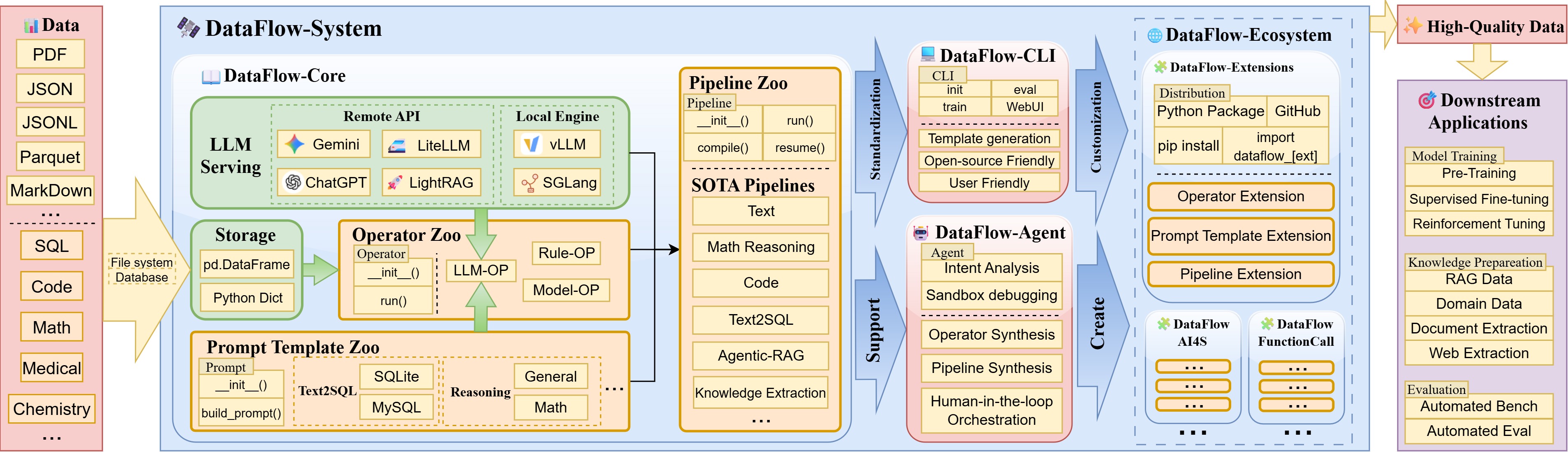
DataFlow: An LLM-Driven Framework for Unified Data Preparation and Workflow Automation

DataFlex: A Dynamic Training Framework
- DataFlex is an advanced dynamic training framework built on top of LLaMA-Factory.
- [Code]
Publications
*: Equal Contribution †: Equal Contribution
-
ICLR'26 Learning What Reinforcement Learning Can't: Interleaved Online Fine-Tuning for Hardest Questions
Lu Ma, Hao Liang, Meiyi Qiang, Lexiang Tang, Xiaochen Ma, Zhen Hao Wong, Junbo Niu, Chengyu Shen, Runming He, Yanhao Li, Bin Cui, Wentao Zhang
International Conference on Learning Representations
-
ACL'26 Leash: Adaptive Length Penalty and Reward Shaping for Efficient Large Reasoning Model
Yanhao Li†, Lu Ma†, Jiaran Zhang, Lexiang Tang, Wentao Zhang, Guibo Luo
Association for Computational Linguistics
-
CVPR'25 Native Visual Understanding: Resolving Resolution Dilemmas in Vision-Language Models
Junbo Niu, Yuanhong Zheng, Ziyang Miao, Hejun Dong, Chunjiang Ge, Hao Liang, Lu Ma, Bohan Zeng, Qiahao Zheng, Conghui He, Wentao Zhang
IEEE/CVF Conference on Computer Vision and Pattern Recognition
-
AAAI'25 Not All Tokens and Heads Are Equally Important: Dual-Level Attention Intervention for Hallucination Mitigation
Lexiang Tang, Xianwei Zhuang, Bang Yang, Zhiyuan Hu, Hongxiang Li, Lu Ma, Jinghan Ru, Yuexian Zou
AAAI Conference on Artificial Intelligence
-
TKDE'25 Acceleration Algorithms in GNNs: A Survey
Lu Ma, Zeang Sheng, Xunkai Li, Xinyi Gao, Zhezheng Hao, Ling Yang, Xiaonan Nie, Jiawei Jiang, Wentao Zhang, Bin Cui
IEEE Transactions on Knowledge and Data Engineering
-
arXiv'26 Training with Harnesses: On-Policy Harness Self-Distillation for Complex Reasoning
Zhengyang Zhao†, Lu Ma†, Wentao Zhang
-
arXiv'26 ANDES: Agent Native Data Evolving Synthesis Tool for Autonomous Instruction Alignment
Zhengyang Zhao, Shengjie Ye, Lu Ma, Hao Liang, Hengyi Feng, Wentao Zhang
-
arXiv'26 Thinking by Subtraction: Confidence-Driven Contrastive Decoding for LLM Reasoning
Lexiang Tang, Weihao Gao, Bingchen Zhao, Lu Ma, Bang Yang, Yuexian Zou
-
arXiv'26 GIFT: Unlocking Global Optimality in Post-Training via Finite-Temperature Gibbs Initialization
Zhengyang Zhao†, Lu Ma†, Yizhen Jiang, Xiaochen Ma, Zimo Meng, Chengyu Shen, Lexiang Tang, Haoze Sun, Peng Pei, Wentao Zhang
-
arXiv'25 DataFlow: An LLM-Driven Framework for Unified Data Preparation and Workflow Automation
Hao Liang, Xiaochen Ma, ..., Lu Ma, ..., Bin Cui, Wentao Zhang
-
arXiv'25 DARO: Difficulty-Aware Reweighting Policy Optimization
Jingyu Zhou†, Lu Ma†, Hao Liang, Chengyu Shen, Bin Cui, Wentao Zhang
Internships
- Tencent AI Lab, Research Intern
- Meituan LongCat, Research Intern
- Alibaba Qwen, Research Intern