-
Learning What Reinforcement Learning Can’t: Interleaved Online Fine-Tuning for Hardest Questions
Lu Ma, Hao Liang, Meiyi Qiang, and 9 more authors
ICLR
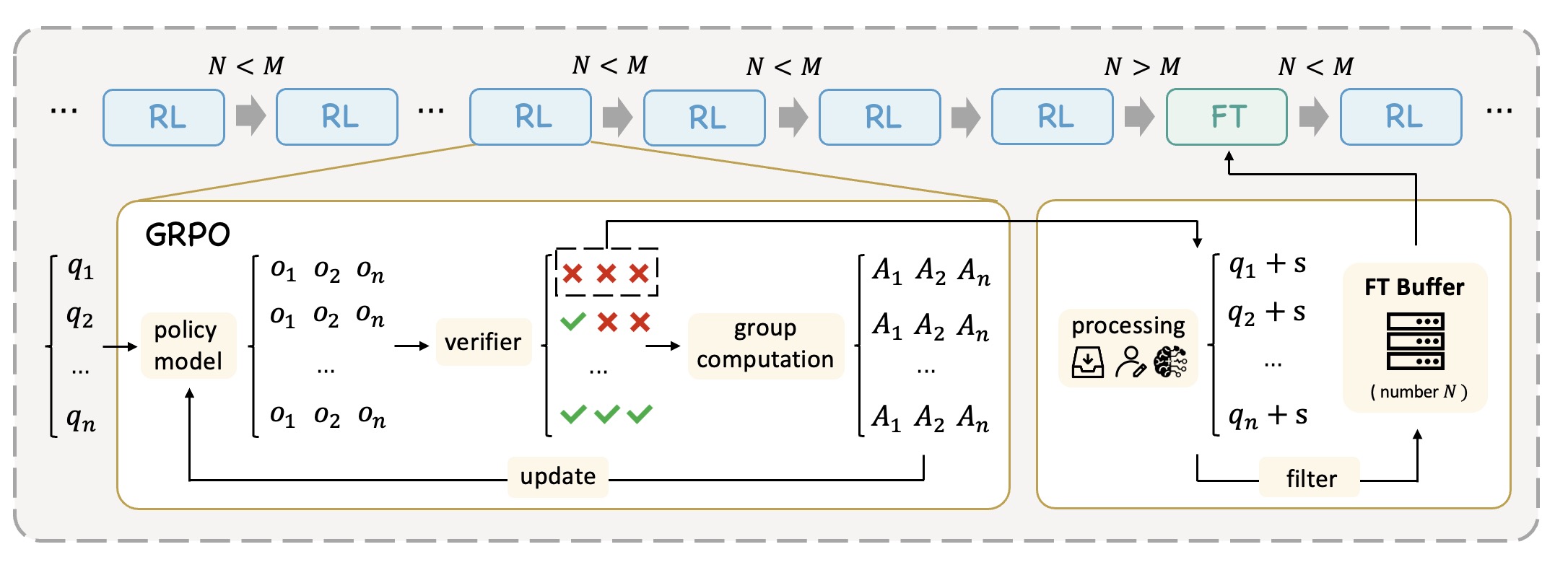
ReLIFT combines reinforcement learning and supervised fine-tuning in an interleaved training framework that expands LLM reasoning capabilities beyond the limits of RL alone.
-
Leash: Adaptive Length Penalty and Reward Shaping for Efficient Large Reasoning Model
Yanhao Li†, Lu Ma†, Jiaran Zhang, and 3 more authors
ACL
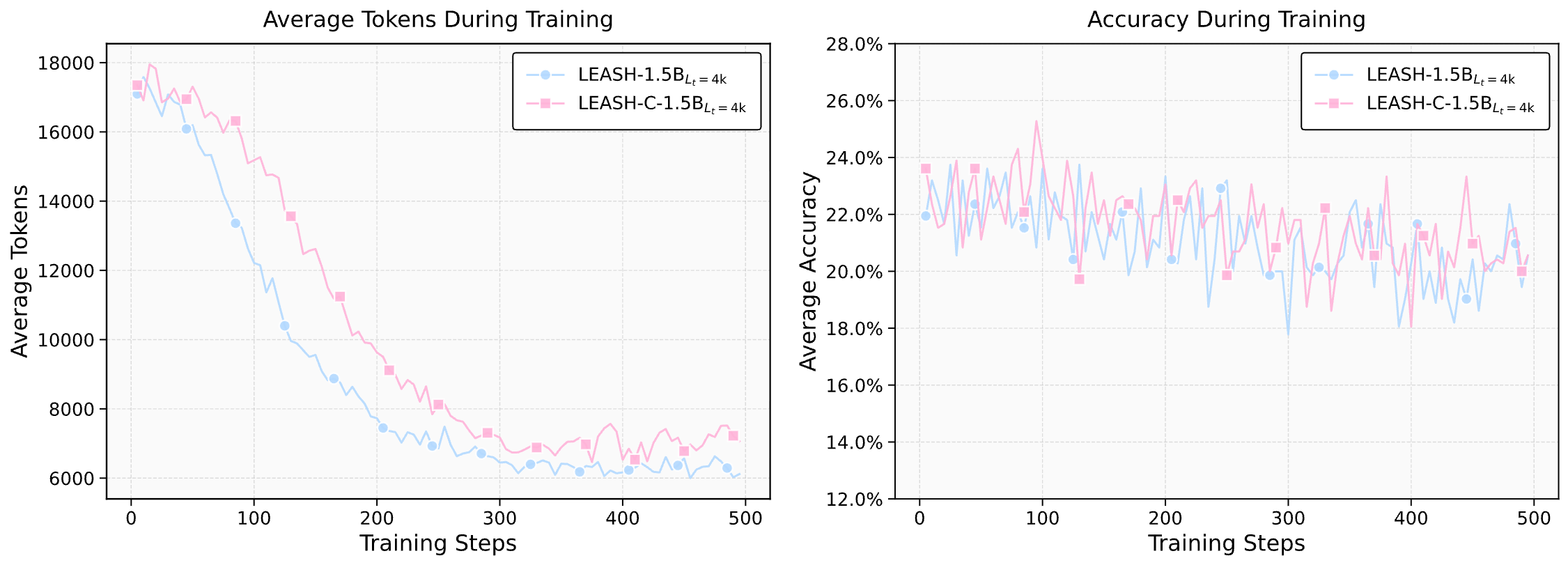
LEASH introduces an adaptive length-penalty mechanism for LLM reasoning using a Lagrangian primal–dual optimization framework, enabling significantly shorter reasoning traces while preserving performance.
-
DataFlex
2025
DataFlex is an advanced dynamic training framework built on top of LLaMA-Factory. It intelligently schedules data during training, supporting dynamic sample selection, domain ratio adjustment, and dynamic weighting, aiming to improve both training efficiency and final model performance.
-
DataFlow
2025
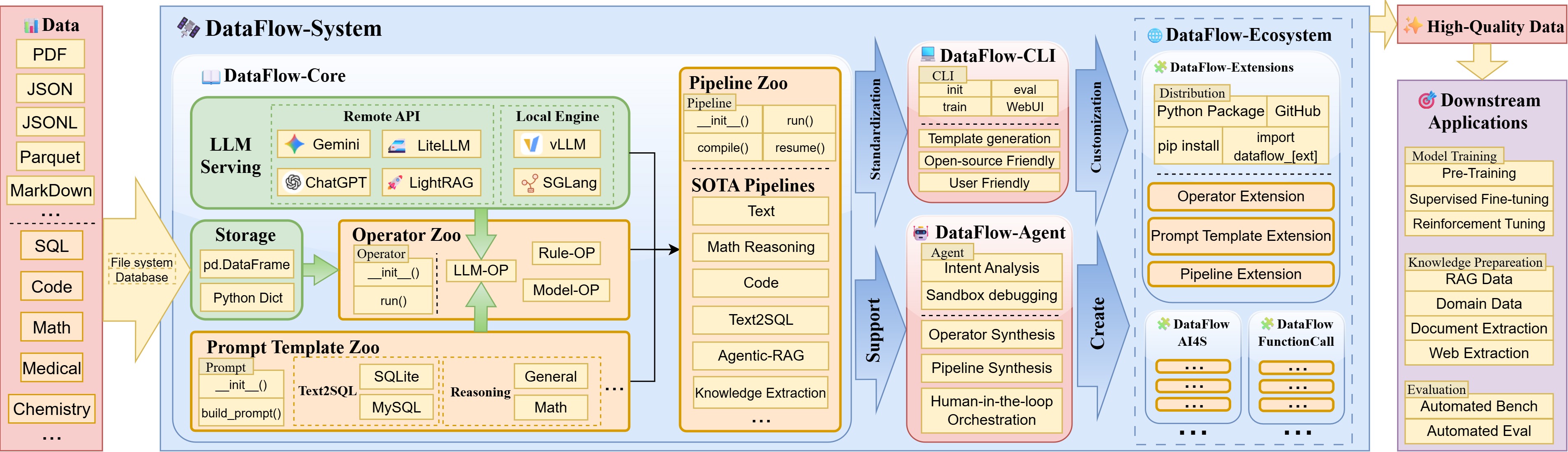
DataFlow is a data preparation and training system designed to parse, generate, process, and evaluate high-quality data from noisy sources (PDF, plain-text, low-quality QA), thereby improving the performance of large language models (LLMs) in specific domains through targeted training (Pre-training, Supervised Fine-tuning, RL training) or RAG using knowledge base cleaning. DataFlow has been empirically validated to improve domain-oriented LLMs’ performance in fields such as healthcare, finance, and law.
† means equal contribution