学 RL 所学不会的
RL 更擅长把模型已有基础的题做得更稳;SFT 更适合教会模型原本完全不会的难题。
基于这个观察,我们提出了 ReLIFT(Reinforcement Learning Interleaved with Online Fine-Tuning):一种将 RL 和在线 SFT 交替进行的训练方法。
当前推理模型的后训练主要以 RL 为主。RL 通过不断试错来学习,泛化性强,但它有一个根本限制:只能在模型自己能生成出来的轨迹上做优化。
这意味着 RL 更容易强化模型已经接近做对的行为。而对于模型完全不会的问题,它连像样的尝试都生成不出来,奖励信号几乎为零,RL 很难帮模型真正跨过这道门槛。
SFT 则相反——只要有高质量示范,就可以直接把新解法教给模型。但如果对所有数据统一用 SFT,又容易退化成模仿,损害模型的泛化能力和 reasoning pattern。
不同难度的题,适合不同的训练方式
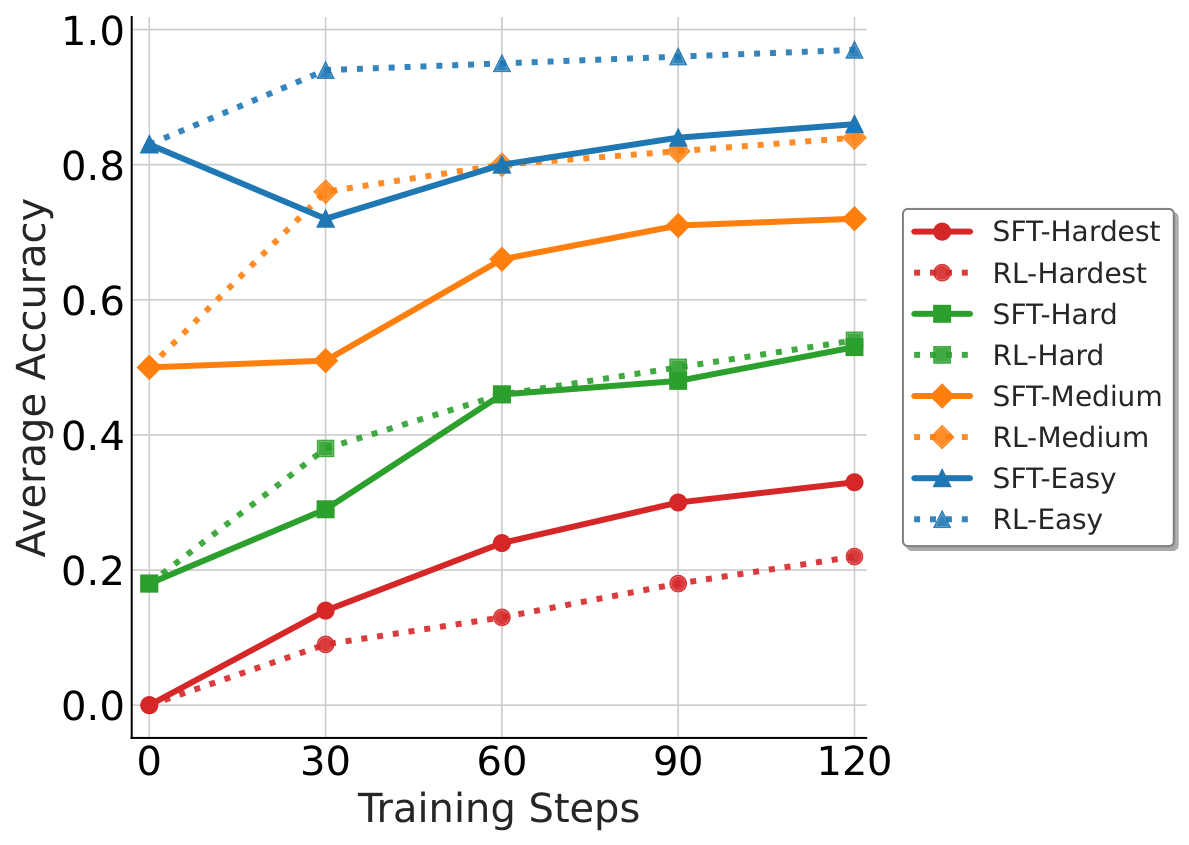
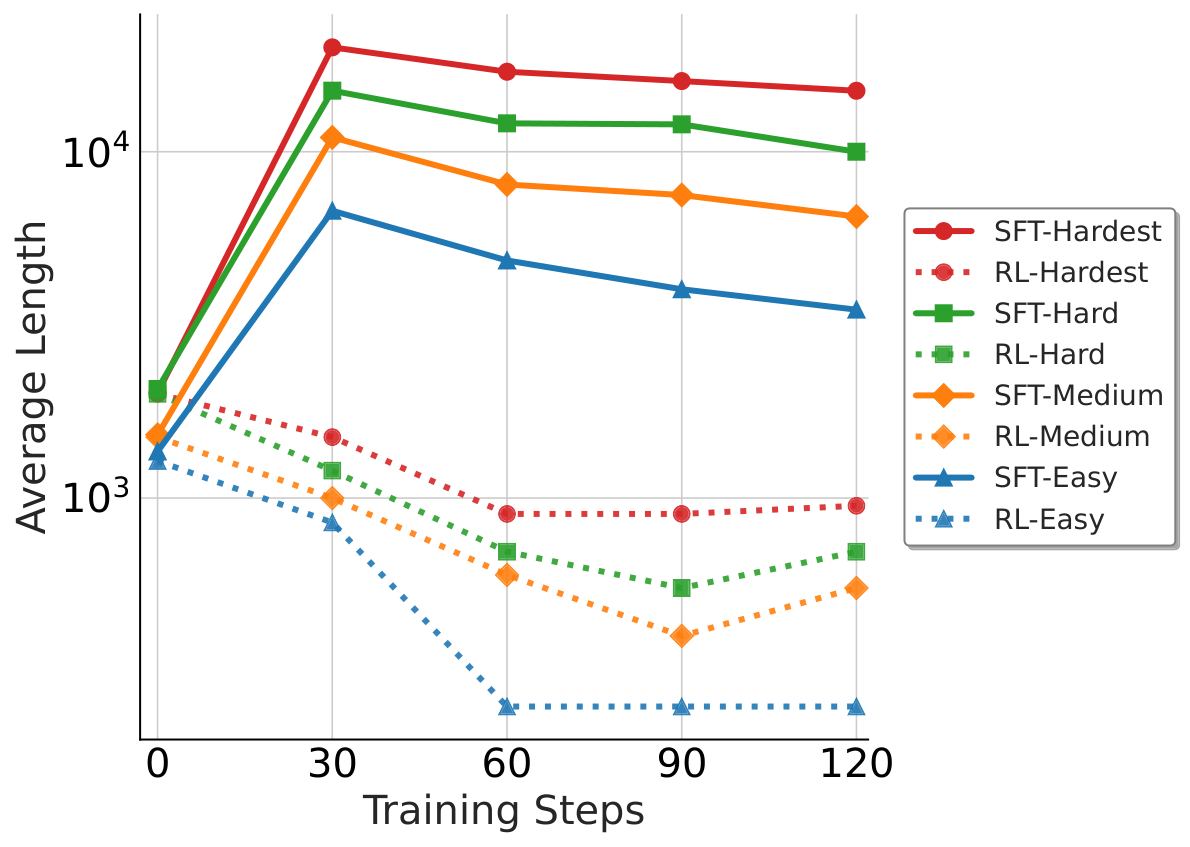
我们把题目按难度分成四档:
- Easy:基本能做对
- Medium:有一定成功率
- Hard:偶尔能做对
- Hardest:多次采样均无法做对
实验结果表明,RL 和 SFT 在不同难度区间各有优势:
- RL 对 Easy / Medium 更有效:模型已有一定基础,RL 可以放大正确行为,提升稳定性和效率。
- SFT 对 Hardest 更有效:当奖励信号不足时,需要先通过示范建立基础能力。
- Length:RL 能让简单题目的推理长度进一步下降,而 SFT 能拉长模型的推理轨迹,对难题有更大的帮助。
ReLIFT
核心思路:RL 做主训练,SFT 只在模型真正无法自学的地方介入。
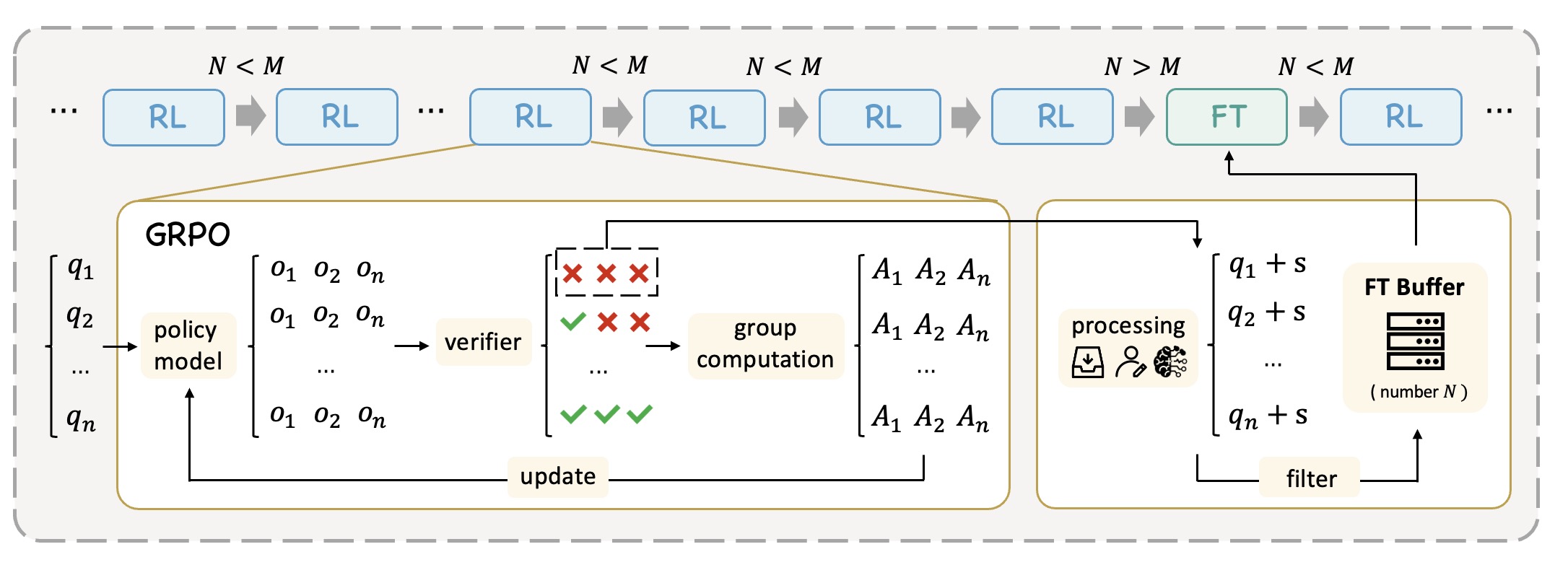
具体流程如下:
- 正常做 RL:按常规方式 rollout、打分、更新。
- 识别 hardest questions:找出当前 rollout 中始终无法做对的题目。
- 为 hardest questions 收集示范:用更强的模型在线生成推理解答,只保留最终答案验证正确的样本。
- 插入小规模 SFT:当 hardest questions 累积到一定数量后,做一次 targeted fine-tuning。
- 继续 RL:在更新后的能力基础上继续循环。
这里 RL 和 SFT 的分工对应了各自的能力边界:
- RL 擅长在已有能力基础上进一步优化,让正确行为更稳定
- SFT 擅长注入新知识,帮模型跨过”完全不会”的门槛
ReLIFT 的关键不是简单叠加两种 loss,而是只在模型自身 RL 确实无法突破的地方才调用 SFT。这样既不需要为所有数据准备大量示范,也不会让 SFT 干扰 RL 本来就能处理好的部分。
在多个 benchmark 上,ReLIFT 整体优于:
- 纯 SFT、纯 RL
- RL + SFT loss 简单混合
- 先 SFT 再 RL 的两阶段 pipeline
- 其他已有的 hybrid 方法
值得一提的是,ReLIFT 使用的示范数据量更少,但由于示范集中在模型最薄弱的地方,数据效率反而更高。
Links
Citation
@article{ma2025learning,
title={Learning What Reinforcement Learning Can't: Interleaved Online Fine-Tuning for Hardest Questions},
author={Ma, Lu and Liang, Hao and Qiang, Meiyi and Tang, Lexiang and Ma, Xiaochen and Wong, Zhen Hao and Niu, Junbo and Shen, Chengyu and He, Runming and Li, Yanhao and others},
journal={arXiv preprint arXiv:2506.07527},
year={2025}
}