从 Post-Training 整体的角度反思 SFT
做这个工作的起点其实是一个挺朴素的疑问:Post-Training 大家都在做先 SFT 后 RL 的两阶段流程,但为什么 SFT 阶段的优化目标从来只盯着”模仿得像不像”,而不去想”这个起点对后续 RL 到底友不友好”?
我们越想越觉得这里有个根本性的错位——问题不是 SFT 或者 RL 哪个不够强,而是 SFT 往往已经把 RL 需要的探索空间压没了,两个阶段的目标其实在打架。
于是就有了 GIFT(Gibbs Initialization with Finite Temperature)。与其纠结 SFT 自身做得好不好,我们想回答一个更前置的问题:什么样的初始化策略,最有利于整个 Post-Training pipeline?
两阶段的内在冲突
现在主流推理模型的后训练大家都很熟悉了:先用高质量示范 SFT 把模型训到”会做”,再接 RL 通过可验证奖励去探索更优解。流程很自然,但仔细想想会发现一个根本矛盾——SFT 的目标是模仿专家轨迹,RL 的目标是探索高奖励轨迹,这两件事本身就有张力。
标准 SFT 用 one-hot supervision 做交叉熵优化,效果就是把概率质量强行压到示范 token 上,分布迅速塌缩。模型看起来确实更”像老师”了,但代价是它也不再愿意走别的路径——而 RL 恰恰需要这些没被完全压死的替代路径来做探索。
所以很多时候不是 RL 学不会,而是 SFT 先把可探索的空间给耗尽了。
从全局目标出发:推导告诉我们什么
既然直觉上觉得 SFT 和 RL 的目标在打架,那不妨把整个 post-training 的全局目标正式写下来。RL 阶段我们真正想优化的是什么?其实就是在最大化任务 reward 的同时,别让策略跑得离 base model 太远:
\[J_{\text{RL}}(\theta) = \mathbb{E}_{x \sim \mathcal{D}, y \sim \pi_\theta} \left[ R(x, y) - \frac{1}{\eta} D_{\text{KL}}\left(\pi_\theta(\cdot|x) \| \pi_{\text{base}}(\cdot|x)\right) \right]\]这个目标其实有一个漂亮的闭式解——最优策略是一个 Gibbs distribution:
\[\pi_{\text{global}}^*(y|x) = \frac{1}{Z_{\text{base}}(x)} \pi_{\text{base}}(y|x) \cdot e^{\eta R(x,y)}\]| 其中 $Z_{\text{base}}(x) = \sum_y \pi_{\text{base}}(y | x) e^{\eta R(x,y)}$ 是归一化常数。 |
这个结果的直觉很清晰:最优策略不是抛弃 base model 去追 reward,而是在 base model 的分布上做一次由 reward 驱动的重加权。 reward 高的轨迹被放大,reward 低的被抑制,但 base model 原有的结构信息始终在底下托着。
那 SFT 在这个全局图景里应该扮演什么角色?既然 RL 的最优解长这样,SFT 作为 RL 的初始化,理想情况下应该尽量靠近这个方向。我们推导出,最优的 SFT 初始化策略应该是:
\[\pi_{\text{sft}}^*(y|x) = \frac{1}{Z(x)} \pi_{\text{base}}(y|x) \cdot e^{\beta R(x,y)}\]这里 $\beta = \eta - \lambda$ 是一个 finite inverse temperature——它控制着”向专家靠拢”的力度。
现在回头看标准 SFT 在干什么:one-hot 的交叉熵损失,本质上就是在说”我要求模型输出和示范一模一样”。在我们的框架里,这对应的恰好是 $\beta \to \infty$ 的极端情况——温度趋向零,分布塌缩成 Dirac delta,只剩下示范答案那一个尖峰。标准 SFT 的损失函数可以写成:
\[\mathcal{L}_{\text{SFT}}(\theta) = -\mathbb{E}_{(x, y^*) \sim \mathcal{D}} \sum_{t=1}^{|y^*|} \log \pi_\theta(y_t^* | x, y_{<t}^*)\]这就是在拟合一个 one-hot target,完全无视了 base model 的分布。所以 distributional collapse 不是 SFT 的”副作用”,而是它目标函数的必然结果。
GIFT:把 SFT 重新定义为有温度的初始化
理论推导告诉我们方向了,剩下的问题是怎么把它变成一个可以训练的目标。
GIFT 的核心想法说起来很直接:不要让模型去拟合 one-hot 的示范 token,而是构造一个 soft target distribution 去拟合。 具体怎么构造呢?对于每个 token 位置 $t$,我们构造一组 advantage-adjusted 的 target logits:
\[\hat{z}_{t,k} = \begin{cases} \log p_{\text{ref}}(k|x, y_{<t}^*) + \beta & \text{if } k = y_t^* \\ \log p_{\text{ref}}(k|x, y_{<t}^*) & \text{if } k \neq y_t^* \end{cases}\]然后对这组 logits 做 softmax 得到 target distribution $\pi_{\text{sft}}^*$。直觉上就是:在 base model($p_{\text{ref}}$)的原始分布上,给示范 token 加一个 $\beta$ 的 bonus,但不是直接把它拉成 one-hot。$\beta$ 越大越接近标准 SFT,$\beta$ 越小越接近 base model 原始分布。
最终的训练损失就是对这个 soft target 做 KL 散度:
\[\mathcal{L}_{\text{GIFT}}(\theta) = -\mathbb{E}_{(x, y^*) \sim \mathcal{D}} \left[ \sum_{t=1}^{|y^*|} \sum_{y_t \in \mathcal{V}} \pi_{\text{sft}}^*(y_t | x, y_{<t}^*) \log \pi_\theta(y_t | x, y_{<t}^*) \right]\]和标准 SFT 的区别一目了然:标准 SFT 的 target 是 one-hot(只有示范 token 有梯度),GIFT 的 target 是一个 soft distribution(所有 token 都有权重,但示范 token 被适度放大)。这样训出来的模型,既学到了示范数据指示的方向,也没有丢掉 base model 原本的结构先验。
为什么这种初始化更适合接 RL
这里有一个经常被忽略的点:后续 RL 通常带 KL 约束,防止策略离初始化策略太远。这意味着初始化策略长什么样,会直接决定 RL 后面还能探索多大的空间。
如果初始化已经极度塌缩,RL 的搜索半径就被压得很小,很多潜在的高奖励轨迹根本采不到。GIFT 的目标就是让初始化本身就和后续 RL 的最优方向对齐——不是把 SFT 和 RL 混在一起训,而是重新定义 SFT 的角色:它应该服务于整个 pipeline 的全局最优,而不是只追求局部的模仿误差最小化。
所以 GIFT 解决的不是单纯的 SFT overfitting,而是两阶段目标不一致这个更底层的结构性问题。
实验
我们在 Qwen2.5-7B 和 Llama-3.1-8B 两个 backbone 上做了实验,训练数据用的是 DeepMath-103k 子集,SFT 之后统一接 GRPO 做 RL。评测覆盖了数学推理(GSM8K、AIME24、AIME25、MATH500)和 OOD 通用能力(HumanEval+、MBPP+),同时和 Direct SFT/RL、Unified Paradigms(LUFFY、ReLIFT)以及各种 SFT-then-RL 的 baseline(SFT + Entropy、Label Smoothing、KD、DFT、ASFT、PSFT)做了全面对比。
下面是完整的结果:
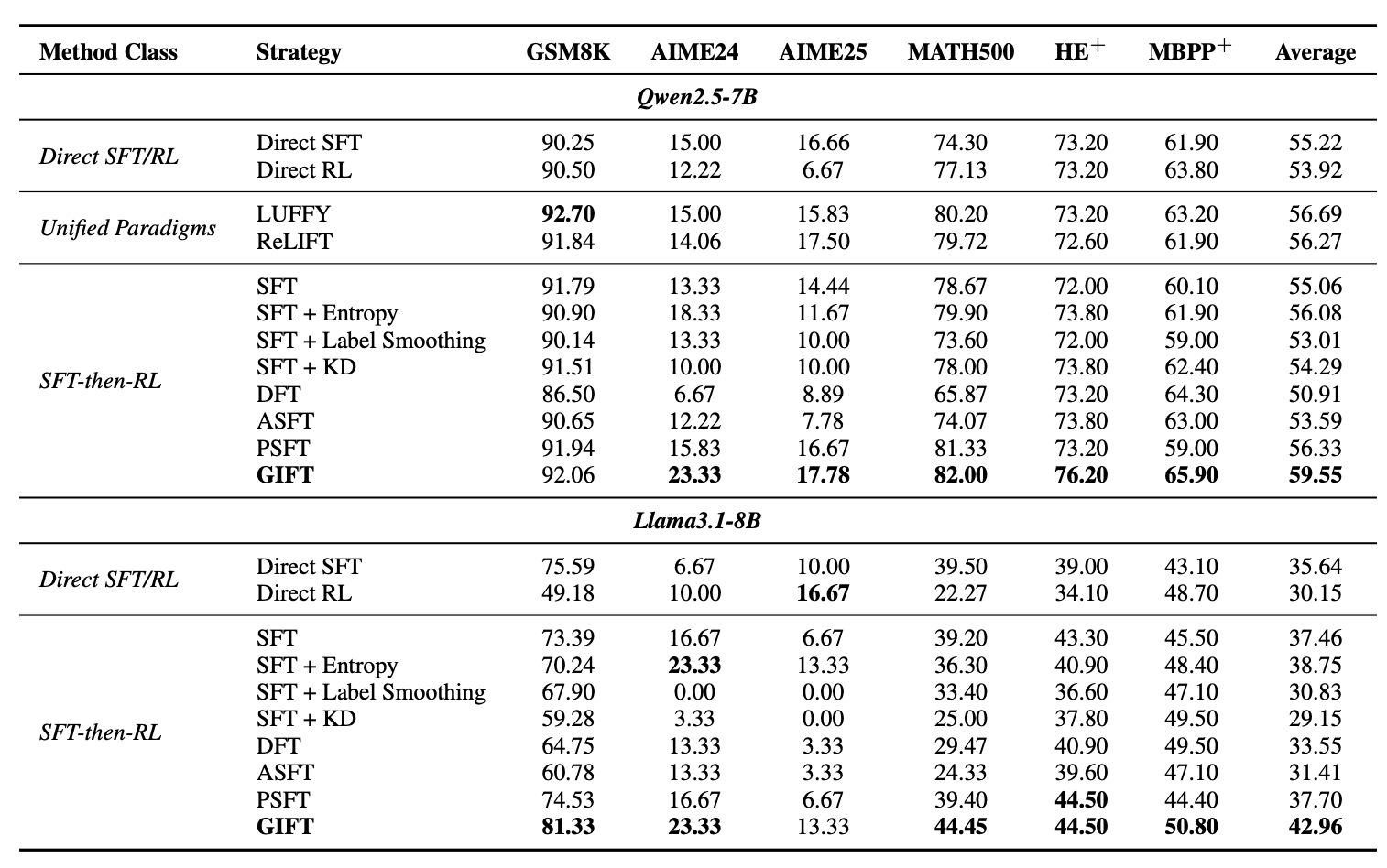
结果里有几个值得展开说的点。
GIFT 在两个 backbone 上都拿到了最好的综合表现。 Qwen2.5-7B 上平均 59.55,Llama-3.1-8B 上平均 42.96,两个 backbone 上都显著领先所有 baseline。特别是在难度较高的 AIME24 和 AIME25 上,GIFT 的优势更明显——Qwen 上分别拿到 23.33 和 17.78,远超标准 SFT 的 13.33 和 14.44。这说明 GIFT 保留的探索空间在面对困难问题时确实能派上用场。
有意思的是和那些”也试图缓解 SFT 塌缩”的方法对比。 SFT + Entropy、Label Smoothing、KD 这些方法的思路都是给标准 SFT 打补丁——加个 entropy 正则、软化 label、用 KD 蒸馏。但它们本质上还是在 SFT 的框架内修修补补,没有从全局目标出发去重新定义 SFT 应该做什么。从结果看,这些方法在某些单项上可能有亮点(比如 SFT + Entropy 在 Llama 的 AIME24 上也拿到了 23.33),但综合表现都不如 GIFT 稳定。
OOD 泛化方面也值得注意。 HumanEval+ 和 MBPP+ 是代码生成任务,和训练数据的数学领域完全不同。GIFT 在 Qwen 上拿到 76.20 / 65.90,在 Llama 上拿到 44.50 / 50.80,都是同组最好。这印证了我们的理论预期:因为 GIFT 没有把分布暴力压到训练领域的极端,base model 对其他领域的通用能力也保住了更多。
最有意思的是探索能力的对比。 我们专门看了 RL 前的 pass@k scaling,发现一个很值得注意的现象:标准 SFT 在 pass@1 上未必更差,但随着采样数增加,它的收益增长明显变慢。以 Qwen2.5-7B 为例,RL 前标准 SFT 的 pass@1 甚至略高于 GIFT(39.79 vs 38.92),但到 pass@8,GIFT 反超到 62.81 vs 59.01。这其实就是 distributional collapse 最直观的证据——单样本看起来还行,但多采几次就没有足够的多样性继续涨点了。GIFT 保留了更宽的输出分布,给后续 RL 留出了真正有用的搜索空间。
关于温度的选择
我们还做了 inverse temperature 的消融分析,结论也符合直觉:太小则约束不够、离专家太远,太大则又逼近标准 SFT 的塌缩极限,最优点在中间某个 finite temperature 区间。而且不同 backbone 的最佳温度还不一样。
这说明问题不是”给 SFT 随便加点 entropy regularization 就行了”,而是需要一个有理论根基的、和全局 post-training 目标一致的温度化初始化框架。
写在最后
这个工作的核心观点其实就一句话:SFT 的目标不应该只是把模型训得像示范,而应该是为后续 RL 保留足够好的探索起点。 这两件事听起来像是一回事,但标准做法下它们的差别其实很大。希望 GIFT 能给大家在设计 post-training pipeline 时提供一个新的思考角度。
Links
Citation
@article{zhao2026gift,
title={GIFT: Reconciling Post-Training Objectives via Finite-Temperature Gibbs Initialization},
author={Zhao, Zhengyang and Ma, Lu and Jiang, Yizhen and Ma, Xiaochen and Meng, Zimo and Shen, Chengyu and Tang, Lexiang and Sun, Haoze and Pei, Peng and Zhang, Wentao},
journal={arXiv preprint arXiv:2601.09233},
year={2026}
}