Long2Short 的第一性原理
推理模型通过长思维链获得了更强的推理能力,但随之而来的是生成长度的显著膨胀。如何在压缩长度的同时尽量保持推理质量,是 Long2Short 问题的核心。
现有的方法大多采用固定的 length penalty,但固定惩罚系数很难适配训练过程中不断变化的长度分布——设得太大会压垮推理质量,设得太小又控制不住长度。
我们的思路是回到第一性原理:把 Long2Short 显式建模为一个带约束的优化问题,用对偶方法推导出自适应的奖励塑造机制。下面是完整的推导过程。
问题建模
推理模型的 Long2Short 本质上是一个约束优化问题:在最大化任务奖励的同时,强制满足生成长度的期望约束。
1. Problem Formulation
形式化地,我们希望在长度约束下最大化期望奖励:
\[\begin{aligned} \max_{\theta} \quad & J_R(\theta)=\mathbb{E}_{x \sim \mathcal{D},\, y \sim \pi_\theta}[r(x,y)] \\ \text{s.t.} \quad & J_P(\theta)=\mathbb{E}_{x \sim \mathcal{D},\, y \sim \pi_\theta}\left[\frac{L(y)}{L_t}-1\right] \le 0 \end{aligned}\]其中 $r(x, y)$ 表示任务奖励,$L(y)$ 表示回复长度,$L_t$ 是目标长度。当平均长度不超过 $L_t$ 时约束满足,反之则违反。
2. Lagrangian / Primal-Dual
利用拉格朗日方法,将带约束优化转为无约束的鞍点问题,交替优化 $\theta$ 和 $\lambda$:
\[\max_{\theta} \min_{\lambda \ge 0} \mathcal{L}(\theta,\lambda)=J_R(\theta)-\lambda \cdot J_P(\theta)\]展开后得到训练中实际使用的增广奖励形式:
\[\mathcal{L}(\theta,\lambda)=\mathbb{E}_{x \sim \mathcal{D},\, y \sim \pi_\theta} \left[ r(x,y)-\lambda \left(\frac{L(y)}{L_t}-1\right) \right]\]策略更新时看到的 reward 不再只是原始任务奖励 r(x, y),而是额外减去一个与超长程度相关的惩罚项。括号内的单样本信号可以理解为增广奖励 r'(x, y),这也是常见 length penalty 的一般形式。
3. 单侧惩罚与截断
直接优化 r'(x, y) 会有一个明显的副作用:当回复比目标更短时,惩罚项变为负数,相当于给短回复发了额外奖励。这会导致模型倾向于过早结束推理,损害思维链质量。
解决方式很直接——只惩罚超长,不奖励过短:
\[r''(x,y)=r(x,y)-\lambda \cdot \max\left(0,\frac{L(y)}{L_t}-1\right)\]进一步地,为了稳定训练,我们将塑造后的奖励截断到固定范围内:
\[r_{\text{LEASH}}=\operatorname{clip}\left(r''(x,y),-1,1\right)\]这两步 clip 各有作用:
- 单侧惩罚:只在长度超过目标时扣分,避免”越短越好”的错误激励。
- Reward clipping:防止长度波动带来过大的 reward scale,提升训练稳定性。
4. 对偶变量的自适应更新
对偶变量 $\lambda$ 控制着惩罚的强度,它的更新依据当前约束的违反程度。由于
\[\nabla_{\lambda}\mathcal{L}=-J_P(\theta)\]我们根据当前批次的平均长度是否超过目标来自适应调整 $\lambda$:
\[\lambda_{k+1}= \operatorname{clip} \left( \lambda_k+\alpha_{\lambda}\cdot\left(\frac{\bar{L}}{L_t}-1\right), \lambda_{\min}, \lambda_{\max} \right)\]其中 $\bar{L}$ 是当前批次的平均生成长度,$\alpha_\lambda$ 是对偶变量的学习率。更新逻辑很直观:
- 当 $\bar{L} > L_t$ 时:$\lambda$ 增大,下一轮训练中对长度的压制增强。
- 当 $\bar{L} < L_t$ 时:$\lambda$ 减小,模型可以把更多优化能力放回任务准确率本身。
这是 LEASH 真正自适应的地方:惩罚强度不是固定常数,而是由训练过程中的实际超标程度动态决定的。
LEASH 算法伪代码
# 输入: 初始策略参数 theta, 初始对偶变量 lambda (通常设为 0)
# 参数: 目标长度 Lt, 学习率 alpha_theta, alpha_lambda, 约束范围 [lambda_min, lambda_max]
对于每一个训练迭代 (iteration k = 1, 2, ...):
1. 采样阶段 (Sampling):
- 从提示词分布 D 中采样一批样本 {x_i}
- 使用当前策略 pi_theta 生成回复 {y_i}
- 计算每个样本的任务奖励 r(x_i, y_i) (如: 正确性判定)
- 记录生成长度 L(y_i)
2. 奖励塑造 (Reward Shaping):
- 对于每个样本, 计算受限增强奖励:
# 关键步骤: 应用单侧惩罚项, 仅对超标回复扣分
penalty_i = max(0, L(y_i) / Lt - 1)
r_shaped_i = r(x_i, y_i) - lambda * penalty_i
# 稳定性处理: 将奖励截断至 [-1, 1] 范围
r_leash_i = clip(r_shaped_i, -1, 1)
3. 策略更新 (Primal Update):
- 使用塑造后的奖励 r_leash 构造损失函数 (如配合 DAPO 或 PPO 算法)
- 通过梯度上升更新策略参数 theta:
theta_{k+1} = theta_k + alpha_theta * Grad_theta(J(theta))
4. 对偶变量更新 (Dual Update):
- 计算当前批次的平均违规程度 (Violation):
violation = mean(L(y_i) / Lt - 1)
- 根据违规情况自适应调整惩罚强度 lambda:
lambda_{k+1} = clip(lambda_k + alpha_lambda * violation, lambda_min, lambda_max)
5. 状态同步:
- 同步最新参数, 进入下一轮训练循环直到收敛
实验结果
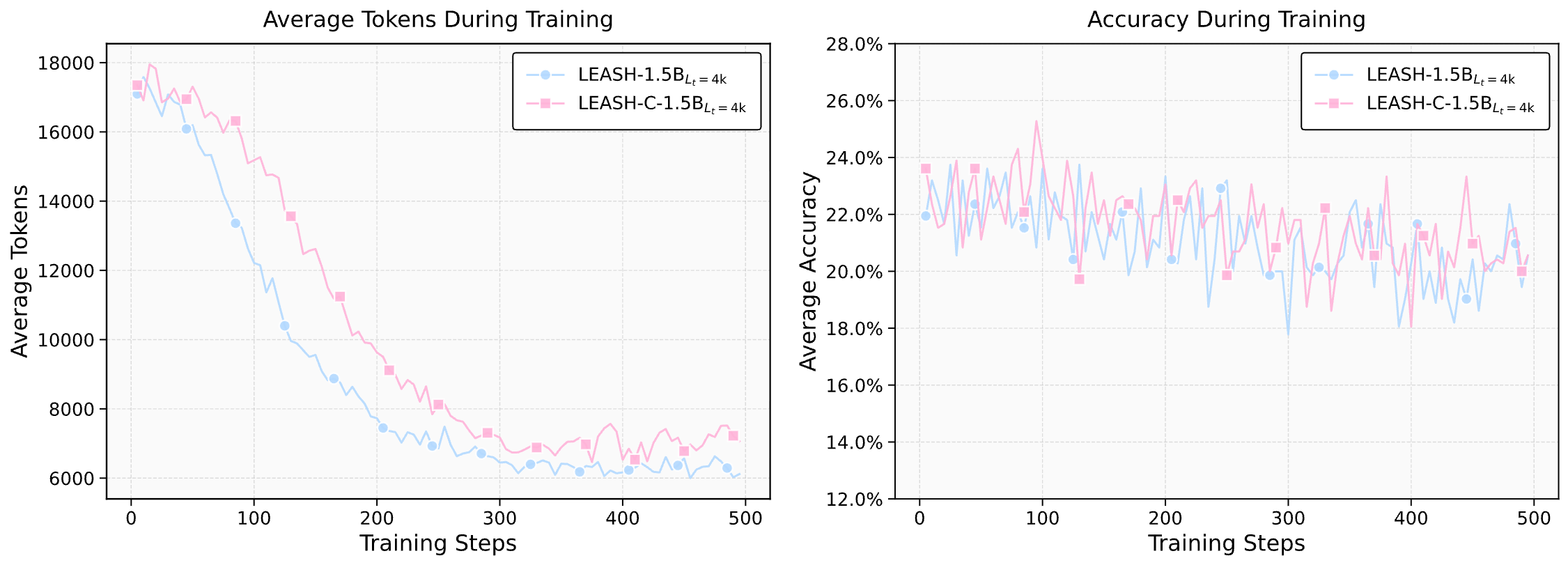
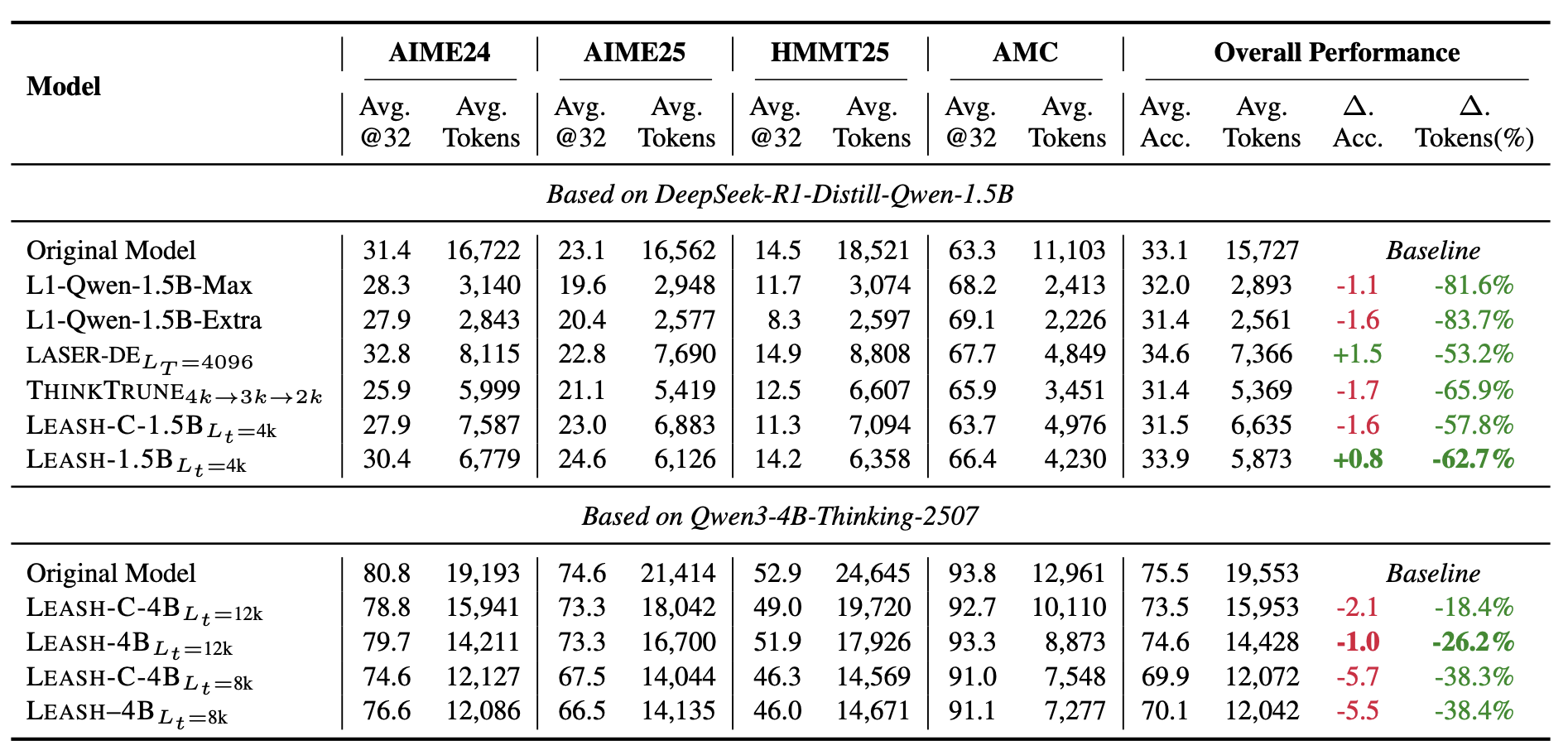
我们在多个推理 benchmark 上验证了 LEASH 的效果。整体来看,LEASH 能够在显著压缩生成长度的同时,保持甚至提升推理准确率。
Links
Citation
@article{li2025leash,
title={Leash: Adaptive Length Penalty and Reward Shaping for Efficient Large Reasoning Model},
author={Li, Yanhao and Ma, Lu and Zhang, Jiaran and Tang, Lexiang and Zhang, Wentao and Luo, Guibo},
journal={arXiv preprint arXiv:2512.21540},
year={2025}
}