让模型自己学会"开挂",然后把外挂扔掉
推理时外挂的 Harness 让模型变强了,但模型自身其实什么都没学到。能不能让模型把 Harness 教会它的东西内化成自己的能力,然后把外挂扔掉?
我们提出了 OPHSD(On-Policy Harness Self-Distillation),通过 on-policy 的自蒸馏,将 harness 增强的推理能力永久写入模型参数,推理时完全不需要外部脚手架。
问题的起点
现在很多推理增强的方法都依赖 inference-time harness——通过在推理时外挂一套控制流程(比如先做计划再解题、先检索再判断),让模型在复杂任务上表现更好。
但问题是:系统变强了,模型本身没变。 Harness 一摘掉,模型立刻打回原形。
这带来几个实际问题:
- 推理成本高:每次推理都要走完整的 Harness 流程,多轮调用模型,token 消耗翻倍。
- 部署复杂:你得维护一整套外部程序来编排模型调用。
- 科学上也说不清楚:模型到底学到了什么?还是只是被外部脚手架撑着?
我们的思路是:让模型在训练时借助 Harness 来学习,学完之后推理时就不再需要它。
OPHSD 框架
下面是 OPHSD 的整体框架图:
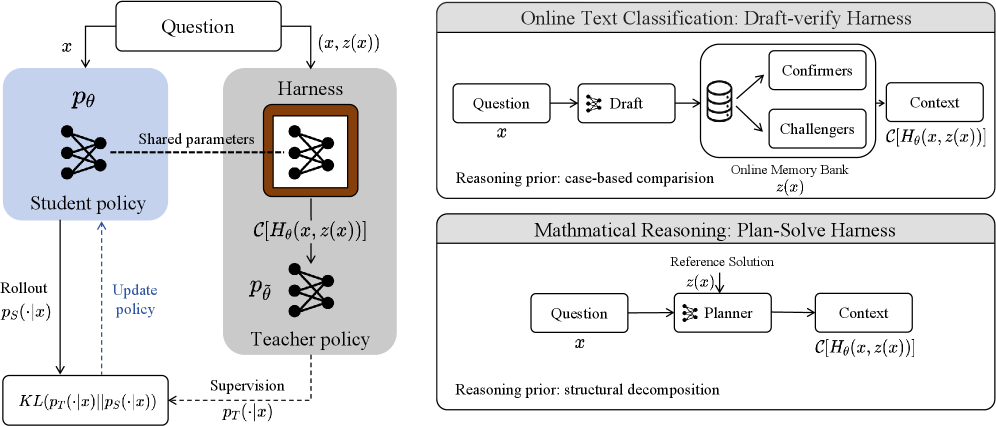
核心想法一句话概括:用 Harness 增强后的模型当老师,教”裸奔”的模型学会同样的推理模式。
训练时模型同时走两条路:
- 学生路径:模型直接从问题 $x$ 生成回答 $\hat{y} \sim p_\theta(\cdot \mid x)$,这是它推理时的真实状态。
- 老师路径:同一个模型在 Harness $H$ 的引导下,借助特权信息 $z(x)$(比如参考答案、相似案例库),经过多步编排后产出一个丰富的推理上下文 $\mathcal{C}[H_\theta(x, z(x))]$。
然后,一个冻结的 teacher 副本 $\tilde{\theta}$ 在这个 Harness 上下文条件下,对学生的 rollout 给出 token 级别的监督信号。训练目标是让学生分布去逼近老师分布:
\[\mathcal{L}_{\text{OPHSD}}(\theta) = \mathbb{E}_{x, \hat{y} \sim p_\theta(\cdot \mid x)} \left[ \frac{1}{\lvert \hat{y} \rvert} \sum_{n=1}^{\lvert \hat{y} \rvert} \text{KL}\left( p_{\tilde{\theta}}(\cdot \mid \mathcal{C}[H_\theta(x, z(x))], \hat{y}_{<n}) \| p_\theta(\cdot \mid x, \hat{y}_{<n}) \right) \right]\]训练完成后,学生已经把 Harness 教的推理模式刻进了参数里,推理时不再需要任何外挂。
两种具体的 Harness 实例
我们实现了两种 Harness,分别针对文本分类和数学推理:
Draft-Verify(文本分类):特权信息是在线记忆库。Draft 阶段检索相似案例生成初步预测,Verify 阶段检索同标签/不同标签案例做双向审视。训练完成后,即使没有记忆库,模型也会在推理链中自发引用和对比案例——只不过这些”案例”来自参数记忆而非外部检索。
Plan-Solve(数学推理):特权信息是参考解答。Plan 阶段生成解题策略草图,Solve 阶段基于策略完成推导。实际上就是把”先想后做”的习惯内化成了参数。
和现有蒸馏方法(如 OPSD)的关键区别在于:OPSD 的特权信息是静态的(直接塞参考答案),而 OPHSD 的特权信息通过动态程序产生——多次调用模型、更新状态、做检索和验证。这意味着我们教的不只是”知道答案”,而是推理的过程本身。
实验结果
我们在文本分类(LawBench、USPTO)和数学推理(AIME24/25、OlympiadBench、HMMT25)上做了全面实验。
文本分类
| 方法 | LawBench (F1) | USPTO (Acc) |
|---|---|---|
| Base | 55.29 | 30.07 |
| Harness | 60.22 | 79.02 |
| GRPO | 62.44 | 90.01 |
| OPSD | 64.25 | 88.01 |
| OPHSD | 69.51 | 90.81 |
OPHSD 比 GRPO 高出 +7.07%,比 OPSD 高出 +5.26%。
数学推理(pass@8)
| 方法 | AIME24 | AIME25 | OlympiadBench | HMMT25 | Avg |
|---|---|---|---|---|---|
| GRPO | 83.33 | 60.00 | 77.94 | 45.00 | 66.57 |
| OPSD | 80.00 | 63.33 | 80.88 | 42.50 | 66.68 |
| OPHSD | 79.17 | 61.67 | 83.82 | 53.33 | 69.50 |
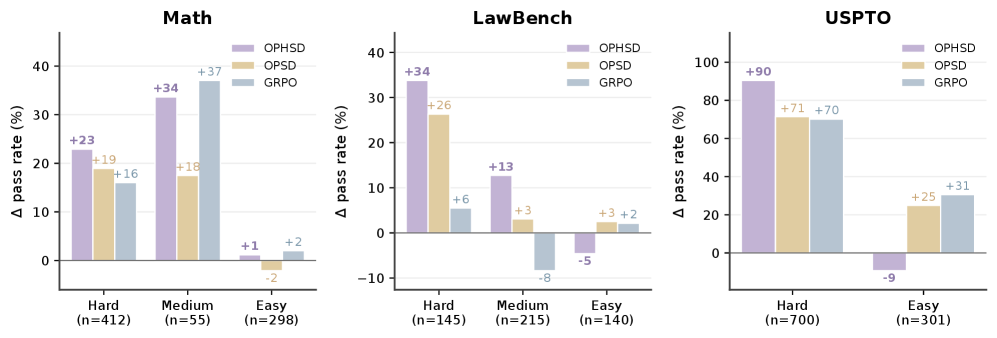
OPHSD 在 HMMT25 上比 OPSD 高出 +10.83%,综合平均 +2.82%。优势集中在困难问题上——LawBench Hard 子集上 +33.8%,USPTO Hard 子集上 +90.4%,越难的问题 OPHSD 的增益越大。
一个具体的例子
光看数字可能还不够直观,我们来看一个数学推理的 case study。
题目: 令 $f(x) = x^1 + x^2 + x^4 + x^8 + x^{16} + x^{32} + \cdots$,计算 $f(f(x))$ 中 $x^{10}$ 的系数。
答案:40
这道题有一个经典陷阱:在展开 $[f(x)]^2$ 时,需要计算哪些指数对 $(i,j)$ 满足 $2^i + 2^j = 10$。显然 $(1,3)$ 和 $(3,1)$ 是两个有序对——但很容易把它们当成同一个无序对,少数一次。
Harness 老师的规划明确指出了这一点:“For k=1: (2,8) and (8,2) are distinct ordered pairs. Total: 2 ways”,然后逐步算出正确答案。
OPHSD 学生推理时(无 Harness):模型自发意识到了这个陷阱——“Since multiplication is commutative, (2,8) and (8,2) might seem the same. But in generating functions… are two distinct ordered pairs. Therefore, the coefficient is 2. Total: 0+2+10+28=40.” 8 次采样中答对 7 次。
OPSD 学生推理时:直接踩进了陷阱——“The only valid pair is (2,8), which occurs once. So the coefficient from [f(x)]² is 1. Total: 0+1+10+28=39.” 8 次采样全部答错。
这个例子很好地展示了 OPHSD 的核心价值:模型不只是记住了答案,而是把老师的审慎推理习惯内化了。OPHSD 学到的是”遇到组合计数时要注意有序 vs 无序”这种 meta-level 的推理模式,而 OPSD 只是在模仿答案的表面形式。
最有意思的发现
学完之后,外挂反而帮倒忙。 训练完成后把 Harness 重新挂回去,不仅没提升,反而可能变差。数学推理上 OPHSD 裸跑 69.50% vs 挂 Harness 69.13%;在 LawBench 上更明显,挂回 Harness 反而掉了 1.10%。这说明 Harness 完全可以只是训练时的临时脚手架,它的好处可以永久转移到模型参数里。
模型真的学会了”引用案例”。 我们用 LLM-judge 检测模型是否在推理链中自发引用案例(推理时没有任何检索):
GRPO / OPSD 的自发引用率始终低于 10%,而 OPHSD 在训练早期就达到 75%,后期稳定在 90% 以上。这意味着 OPHSD 把”调取相似案例来辅助判断”这个推理习惯写进了权重里。
推理链没有坍缩。 和 OPSD 不同(OPSD 后期推理链会逐渐变短、坍缩),OPHSD 在整个训练过程中维持了稳定的输出长度,说明蒸馏过程没有以牺牲推理深度为代价。
写在最后
核心观点就一句话:推理时的 Harness 不应该是模型永远的拐杖,而应该是训练时的临时脚手架。 通过 on-policy 的自蒸馏,Harness 教给模型的不是答案,而是推理的结构和习惯。训练完成后,脚手架可以拆掉,模型已经学会了自己站稳。
当然,这项工作也有明确的局限和未来方向。我们目前主要关注偏 reasoning 的 Harness,例如检索相似案例后再判断、先规划再求解等。对于真实工具调用、长程交互、多模态反馈等更复杂的 Harness,其过程性能力能否同样稳定地蒸馏进模型参数中,仍然需要进一步验证。
Links
Citation
@article{zhao2025ophsd,
title={Training with Harnesses: On-Policy Harness Self-Distillation for Complex Reasoning},
author={Zhao, Zhengyang and Ma, Lu and Zhang, Wentao},
journal={arXiv preprint arXiv:2605.08741},
year={2025}
}